Every byte counts - Floating-point in less than 1 KB
How expensive in terms of code size are floating-point operations if the CPU does not have an floating-point unit (FPU)?
In this article, I will investigate, based on Embedded Studio for ARM and a generic Cortex-M3 device, how big (or small) an entire application using basic float operations, add, sub, mul, and div, can be.
Since we started licensing our Floating-Point Library, outside of Embedded Studio and outside of the SEGGER RunTime Library, we are seeing a lot of interest. We have published performance values, but for some people size matters more than speed. Here is a quick look at how small our floating point code is, based on a small project in Embedded Studio, which is also provided and easily allows reproduction. The same approach can be used to benchmark other tool chains, so this post can be used as a tutorial to find out how small the components of a floating point library are.
(For a closer look at performance, see blog article Floating-point face-off, part 2: Comparing performance)
Start project
As the starting point, I used the small project I generated in my previous blog article, titled Every byte counts – Smallest Hello World. It generates a 117 byte program that runs on any Cortex-M3, M4, M7 CPU or in a simulator, printing “Hello World!”. It looks as follows:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#include "stdio.h"
int main(void) {
printf("Hello world!");
}
|
To be on the safe side, I decided to rebuild it, by pressing ALT-F7.
The result is as expected: 117 bytes.
Adding floating point code
How do we now add floating point code?
Actually, this is quite easy. We simply add a floating point computation and make sure the result is used by the program, so the compiler does not optimize it away.
In order to do that, I use the computed result in the string to output. This also gives me a chance to verify the result.
To test multiplication, I use the following code:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int main(void) {
float f;
f = 1.0;
while (1) {
printf("Result = %fn", f);
f *= 3.0;
}
}
|
Pressing F5 starts the debugger. After setting a breakpoint and hitting this a few times, I see the below:
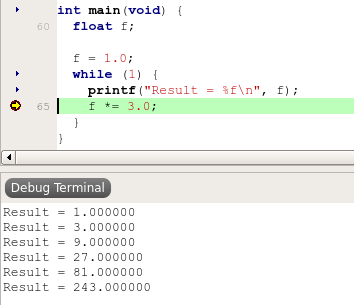
Looking good, just as expected.
What is the size of the floating point library code?
Now let’s look at the program size, which Embedded Studio reports to be 401 bytes. When we subtract the original 117 bytes for “Hello World!” we get
a difference of 284 bytes. To be fair, we need to also take into account that main is now bigger, up 28 bytes from 29 to 57, so the size of the multiplication code is really just 256 bytes. Not bad for a floating point multiplication completely done in software!
But to be sure, let’s look at the disassembly of main.
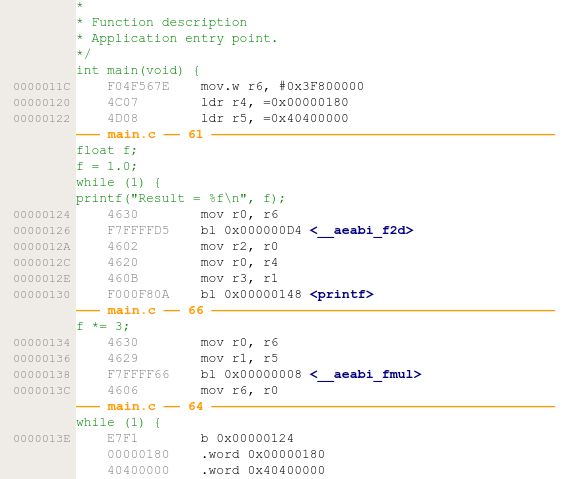
We can see that __aeabia_fmul() is called for the multiplication, but before the printf(), __aeabi_f2d() is called. This is because printf() expects its arguments to be double precision (64-bit) rather than single precision (32-bit) floats. So as the name implies, __aeabi_f2d() converts from float to double.
We therefore also need to subtract its code size, as it is not multiplication related, just related to outputting the number.
Looking at the ELF file or the map file, we find that the size of __aeabi_f2d() is
52 bytes. Subtracting this from our original 256 bytes brings us to 204 bytes.
For verification purposes, let’s look at the map file.
__aeabi_f2d 000000d5 0x34 4 Code Wk floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
__aeabi_fmul 00000009 0xcc 4 Code Wk floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
It confirms what we have computed. For floating point multiplication, only a single routine is required. This routine is blazingly fast, but what we are looking at here is the code size: An amazing 204 bytes!
Note that this is the size of the multiplication code in the library. Every call now only adds a few bytes. A quick test shows us that a call is about 8 bytes.
By simply multiplying a second time in our small program we see that code size for the entire application goes up to 409 bytes:
|
1
2
3
4
5
6
7
8
9
10
|
int main(void) {
float f;
f = 1.0;
while (1) {
printf("Result = %fn", f);
f *= 3.0;
f *= 3.0;
}
}
|
To be on the safe side, and to better understand what code the compiler has generated, let’s look at the disassembly by opening the ELF file.
We find the following:
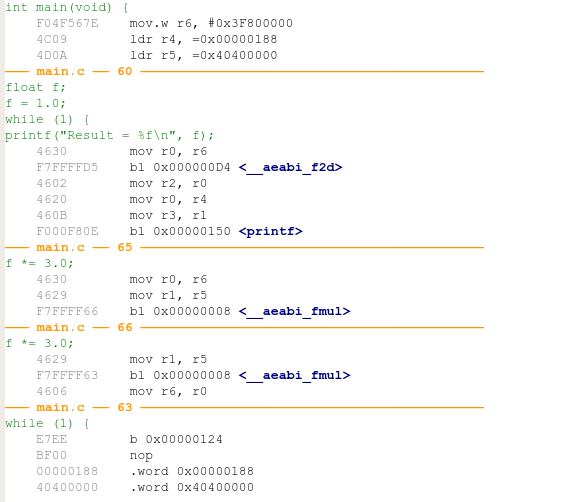
We can see that in this case, the call to the multiplication routine actually requires 8 bytes.
Testing Add and Subtract
In order to do the same thing for add, I simply use addition instead of multiplication. The output looks as expected:
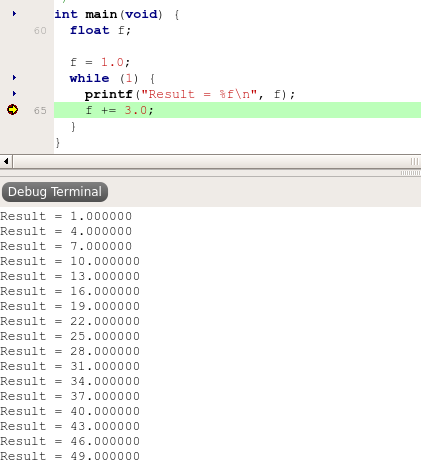
Program size is 481 bytes, so 80 bytes more than when multiplying.
For subtracting: Program size is 489 bytes,
code size of subtraction code is (489 -197) bytes = 284 +8 bytes.
Why is code for adding and subtracting bigger than code for multiplying floats?
The answer is quite simple:
In floating point, the mantissa is always scaled, so multiplying two values basically means multiplying the mantissas and adding the exponents, whereas for adding and subtracting, an extra step is required, namely shifting the mantissas to the same position before adding.
That all sounds expensive and complicated, but it can actually be done very efficiently.
Adding and subtracting in the same program
Let’s see what happens when we add and subtract in the same program. We use the below and look at the result:
|
1
2
3
4
5
6
7
8
9
10
|
int main(void) {
float f;
f = 1.0;
while (1) {
printf("Result = %fn", f);
f += 3;
f -= f;
}
}
|
The compiler now generates a cal to __aeabi_fsub(). The map file tells us the divide code needs only 8 bytes:
__aeabi_f2d 0000012d 0x34 4 Code Wk floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
__aeabi_fadd 00000009 0x11c 4 Code Wk floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
__aeabi_fsub 00000125 0x8 4 Code Wk floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
How does this work?
Stepping into the subtraction routine reveals the trick:

Subtract simply inverts the sign of the second operand and uses the addition code. So in the presence of floating point addition, floating point subtraction “costs” only 8 bytes.
(Note: In speed optimized variants, subtraction actually has its own block of code to avoid the 2 instruction penalty that occurs when jumping to the addition code.)
Division
Division in floating point is actually easy to implement using shift and subtract.
Unfortunately, the performance of such a simple implementation is poor, so we use a fast algorithm using Cortex-M3 (and up) UDIV instruction.
This brings up the code size for divide, but not too much:
We end up with a program size of 421, so a library code size of (421 – 197) bytes = 224 bytes.
I looked at the output window after a few loops, showing correct values:
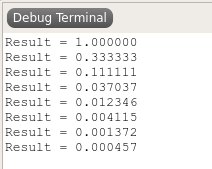
All in!
Let’s write a program that uses all 4 basic operations in a single program.
To avoid giving the compiler a chance to optimize some of the computation, we use a second variable and declare it as volatile.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
volatile float b = 2;
int main(void) {
float a;
a = 1.0;
while (1) {
printf("Result = %fn", a);
a += b;
a *= b;
a -= b;
a /= b;
}
}
|
Running it, the output looks good:
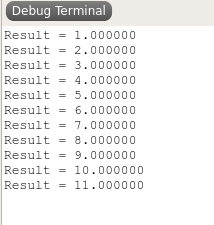
The result is quite impressive.
983 bytes for the entire program! This includes everything: The startup code, printf code (host side evaluation), the part of the floating point library that does addition, subtraction, multiplication, division, as well as a single-precision (32-bit) to double precision (64-bit) conversion routine and our small application program including the short string.
Incredible!
Try this with any other tool chain!
Actually, it was so incredible that I had to verify it.
Turns out this is correct. Our application does actually call all 4 arithmetic functions used in the program.

The map file confirms all 5 functions are linked in.
.text.__aeabi_fadd Code 00000008 0x11c 4 floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
.text.__aeabi_fsub Code 00000124 0x8 4 floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
.text.__aeabi_fmul Code 0000012c 0xcc 4 floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
.text.__aeabi_fdiv Code 000001f8 0xe0 4 floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
.text.__aeabi_f2d Code 000002d8 0x34 4 floatasmops_arm.o (libc_v7em_t_le_eabi_small.a)
Complete floating point operations and output to terminal in less than 1kByte of ROM!
Quite impressive, I find…
But I think I already said that. 🙂
Conclusion
Floating point operations can be performed very efficiently in software.
The code in Embedded Studio and the SEGGER library is highly optimized.
A typical Cortex-M CPU can do multiple million floating point operations per second, so using floating point on a CPU without FPU is perfectly reasonable, both from a performance as well as a code size perspective. Dedicated FPUs for me really only make sense for applications that use floating point operations intensively.
Our developers, who have developed this great code over a period of more than 20 years, have done a great job!
Note that the SEGGER floating point library we are looking at has been hand optimized for ARM processors. There are different variants for the different CPUs, such as ARM (including THUMB-2, legacy ARM-V4 and modern 32- and 64-bit CPUs), as well as RISC-V, including 64-bit and RISC-V E cores.
In another post, I might look at high level functions, such as sin(), cos(), ln().
For now, I end this and encourage you try this yourself, with SEGGER Embedded Studio and / or any other tool chain.
I’d be very surprised if you can achieve the same level as Embedded Studio (less than 1kByte) for the same application program when using another tool chain.
And keep in mind that we can do even better. This code is using a speed optimized variant of float division. With size optimized code, the program could be even smaller.
The entire project used is here.
24-08-2020
|







 Read more
Read more





